Многие знают, что для того, чтобы объединить текст в двух ячейках достаточно воспользоваться функцией СЦЕПИТЬ (CONCATENATE), однако, как быть, если необходимо не объединить, а наоборот разделить текст в ячейке?
Смотрите также видеоверсию статьи «Как разделить текст в MS Excel».
Если количество символов, которое необходимо отделить известно (не важно справа или слева), тогда можно воспользоваться функциями ЛЕВСИМВ (LEFT) или ПРАВСИМВ (RIGHT), в зависимости с какой стороны необходимо выделить определенное количество символов.
Однако, как быть, если необходимо разделить ячейку в которой заведомо не известно количество символов, которые нужно отделить, а известно лишь сколько частей необходимо получить в результате операции. Самым простым примером такой ситуации может быть необходимость выделить из ячейки в которой занесено ФИО человека, отдельно фамилию, имя и отчество. Фамилии у всех разные, поэтому заранее узнать количество символов, которые необходимо отделить, не получится.
На Ваше обозрение представим два способа разделения текста. Один очень быстрый – для тех кому надо просто разделить текст заменив имеющийся, а второй с использованием формул.
Первый способ – супер быстрый
На самом деле в MS Excel существует встроенная возможность быстрого разделения текста в ячейке, если там присутствует или присутствуют разделитель/разделители (например, простой пробел или запятая). Причем таких разделителей может быть несколько, т.е. текст будет разделятся если в строке присутствует или пробел, или точка с запятой или запятая и т.д.
Для этого необходимо выделить ячейки с текстом, который необходимо разделить и воспользоваться командой «Текст по столбцам».

В англоязычной версии MS Excel данная команда звучит как «Text to Columns» вкладки «DATA».

После несложных подсказок мастера (на самом деле, в нашем примере после выбора разделителя – пробела можно смело жать «Готово»)
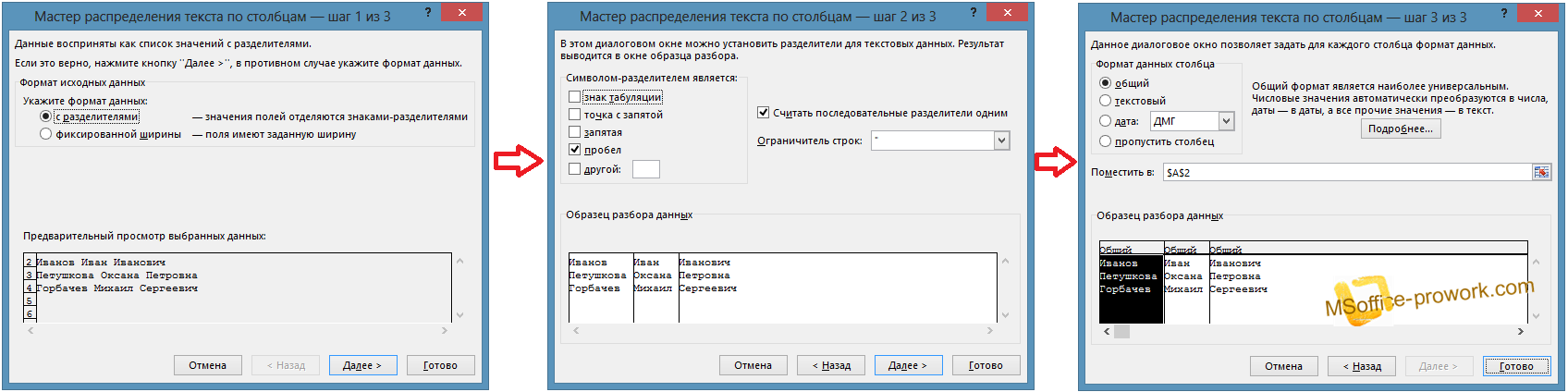
А вот и, собственно, результат.

Второй способ – с использованием формул
В такой ситуации понадобится сочетание функций: ПОИСК (SEARCH) и ПСТР (MID). Для начала, с помощью первой находим пробел между словами (между фамилией и именем и именем и отчеством), а потом подключаем вторую для того, чтобы выделить необходимое количество символов. Грубо говоря, первой функцией определяем количество символов, а второй – уже разделяем.
Кроме того, поскольку разделительного знака в конце строки нет, то количество символов в последнем слове (нашем случае – отчестве) вычислить не удастся, но это не проблема, достаточно указать заведомо бОльшее количество символов в качестве аргумента «число_знаков» функции ПСТР, например, 100.
Рассмотрим вышесказанное на примере. Сначала, для лучшего понимания, разнесем формулы и, таким образом, разделим весь процесс на два этапа.


Для того, чтобы определить количество символов, которые необходимо выделить в строке, необходимо определить позиции разделителей (в нашем случае пробела) их будет на один меньше нежели слов в ячейке.
Поскольку информация о количестве необходимых символах получена, следующим этапом будет использование функции ПСТР (MID).


Здесь, в качестве аргументов, используются промежуточные значения, полученные с помощью функции ПОИСК. Для последней колонки количество символов неизвестно, поэтому было взято заведомо бОльшее количество символов (в нашем случае 100).
Теперь попробуем соединить промежуточные расчеты в одну формулу.


Если текст в ячейке необходимо разделить лишь на две части, то необходимо произвести поиск лишь одного пробела (либо другого разделителя, который находится между словами), а для разделения на 4 и больше частей формулу придется усложнить поиском 3го, 4го и т.д. разделителей.


